
A la hora de construir soluciones que integran modelos de lenguaje generativos como GPT-4o, Gemini 1.5 Pro o Claude 3.5 Sonnet, me he encontrado con dificultades para comunicar correctamente conceptos clave. Uno de los más importantes es el concepto de entrenar un modelo.
Cuando estoy rodeada de perfiles sin experiencia en Inteligencia Artificial, suelo escuchar cómo intentan usar la jerga del área, pero muchas veces de forma incorrecta. Un ejemplo claro es cuando afirman que «estoy entrenando un modelo» mientras ajusto el comportamiento de un modelo preentrenado. ¿Es esto correcto? No.
En este artículo, te explicaré dos conceptos clave para entender mejor este tema:
¿Qué significa entrenar un modelo de Inteligencia Artificial?
El concepto de entrenar un modelo proviene del mundo del Machine Learning y el Deep Learning. Aunque al hablar de Inteligencia Artificial Generativa utilizamos el mismo término, la escala y los recursos necesarios pueden variar drásticamente. Veamos primero un ejemplo sencillo: una regresión lineal.
Regresión lineal: el modelo más simple
La ecuación de una recta es y = ax + b, donde:
- y: Predicción o resultado que queremos obtener.
- x: Característica o atributo utilizado para predecir y.
Por ejemplo, si tenemos una hoja de cálculo con dos columnas: «edad» y «ahorros», podríamos intentar calcular los ahorros de una persona dada su edad. En este caso:
- x: Edad.
- y: Ahorros.
- a y b: Parámetros que definen la pendiente y el desplazamiento de la recta.
Al entrenar un modelo, lo que hacemos es ajustar los valores de a y b utilizando un conjunto de datos. Inicialmente, los valores son aleatorios, pero mediante un proceso iterativo, el modelo ajusta estos parámetros para minimizar el error entre las predicciones (y) y los datos reales.
Una foto que me gusta mucho es la siguiente en la que se ve cómo partimos de una recta inicial (completamente aleatoria al principio, ya que los pesos empiezan con valores aleatorios) y cómo vamos iterando para ir ajustando los pesos (a y b) par que la recta defina de la forma más precisa a nuestro conjunto de datos (la hoja de cálculo que teníamos con valores para sexo y ahorros).
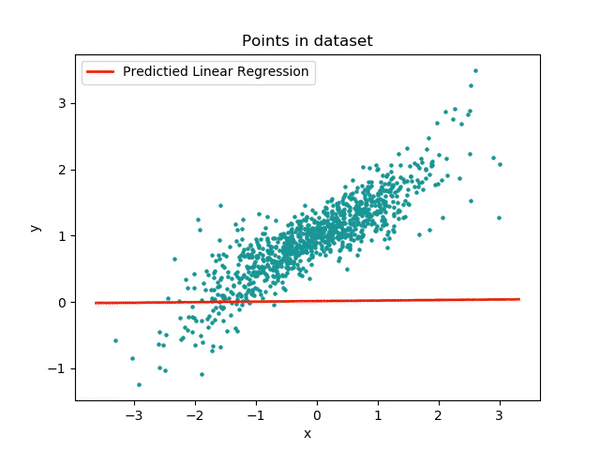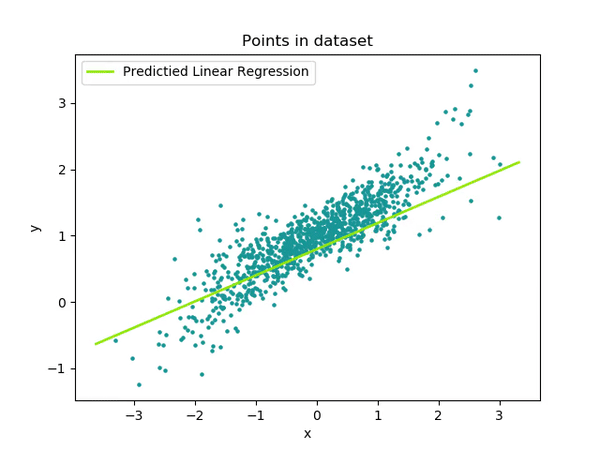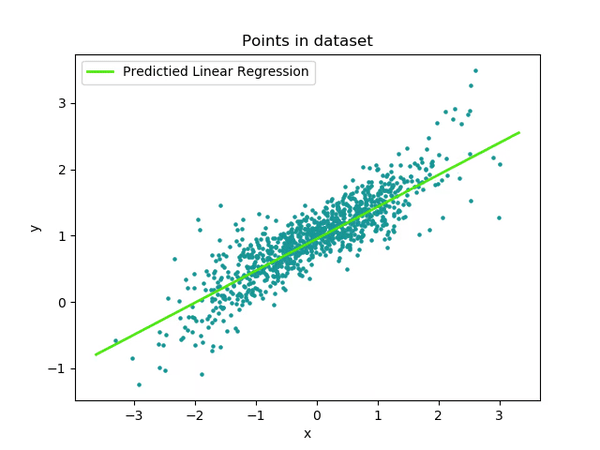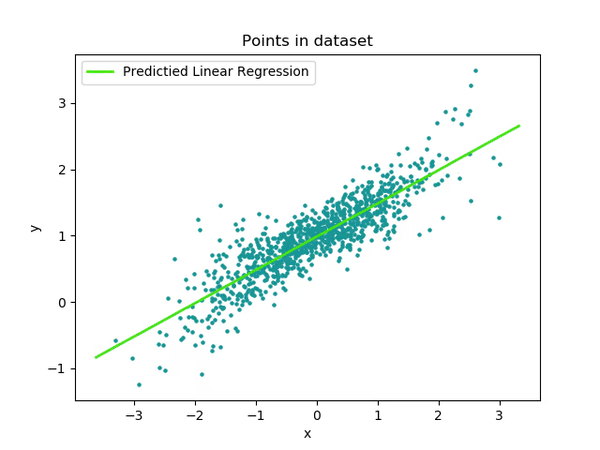
Lo que podemos ver es que cuando entrenamos un modelo, siendo nuestro modelo en este caso algo tan sencillo como y = ax + b, lo que estamos haciendo es modificar el valor de sus parámetros. Para ello, necesitamos datos de los que pueda aprender.
En el caso de los modelos generativos basados en Deep Learning, como GPT-4o, la cantidad de parámetros no es 2 (como en la regresión lineal), sino que hablamos de miles de millones de parámetros. Entrenar un modelo de esta escala implica:
- Definir la arquitectura del modelo: Por ejemplo, redes neuronales profundas o transformers.
- Asignar valores iniciales aleatorios a los pesos.
- Alimentar el modelo con grandes conjuntos de datos para ajustar los pesos y minimizar errores en las predicciones.
Este proceso requiere enormes recursos computacionales y un presupuesto considerable, algo que solo unas pocas empresas pueden permitirse.
Ingeniería de Prompt: Ajustando modelos preentrenados
Cuando trabajamos con modelos como GPT-4o o Gemini, no los entrenamos desde cero. Estos modelos ya han sido entrenados por empresas como OpenAI o Google utilizando vastísimos conjuntos de datos. Lo que hacemos es adaptarlos a nuestros casos de uso mediante técnicas como la ingeniería de prompt.
¿Qué es la ingeniería de prompt? La ingeniería de prompt consiste en diseñar las instrucciones (prompts) que damos al modelo para obtener resultados específicos. Esto incluye:
- Definir el comportamiento y la «personalidad» del modelo.
- Establecer el formato de las respuestas (estructura, estilo, restricciones).
- Ajustar las instrucciones para maximizar la precisión y relevancia del resultado.
Imagina que un cliente necesita que la IA devuelva un JSON para que otra API lo procese. Un buen ingeniero de prompt puede construir una instrucción que garantice que el modelo genere la respuesta en el formato exacto solicitado.
Beneficios de la ingeniería de prompt
- Eficiencia: Ajustar prompts es mucho más rápido que entrenar un modelo desde cero.
- Reducción de costes: Evita el gasto asociado al entrenamiento y a la gestión de grandes conjuntos de datos.
- Aprovechamiento del conocimiento general del modelo: Los modelos preentrenados ya tienen una base de conocimiento amplia y robusta.
Conclusión
Trabajar con modelos generativos no implica entrenarlos. La clave está en saber formular prompts efectivos que permitan obtener los resultados deseados. Esto, combinado con un buen conocimiento de cómo evaluar y versionar prompts, hace que la ingeniería de prompt sea una herramienta poderosa en el desarrollo de soluciones basadas en IA Generativa.
Si quieres aprender más sobre este tema, ¡sigue mis publicaciones y explora mis artículos en LinkedIn!
Deja una respuesta