
En el mundo de los grandes modelos de lenguaje muchas veces habrás escuchado hablar, o leído, sobre el tamaño de ventana de contexto (o context window size en inglés) de un modelo. Sin embargo, puede ser que no sepas qué significa esto realmente.
Te animo a que hagas las siguiente prueba: abre ChatGPT, dile «hola qué tal?» y ahora coge un documento en PDF super extenso que tengas y suéltalo en ChatGPT (siempre y cuando ChatGPT lo acepte). Hazle un par de preguntas más, pídele quizás un resumen del documento, su opinión, y ahora cámbiale de tema, dile que te genere un texto de unas 20.000 palabras para un artículo para LinkedIn hablando sobre el cambio climático. ¿Lo has mareado lo suficiente y proporcionado la suficiente interacción? ¡Dile ahora que te recuerde cuál ha sido el primer mensaje que le has mandado! Aquí puede pasar varias cosas:
- Que la cantidad de texto intercambiada en los mensajes no hayan sido los suficientes y que ChatGPT recuerde perfectamente cuál fue tu primer mensaje.
- Justo lo contrario, que ChatGPT ya no recuerde el primer mensaje de la conversación porque ha perdido ese contexto.
¿Por qué pasa esto?
Todos los modelos de lenguaje presentan un tamaño de ventana de contexto. A día en el que escribo este artículo GPT-4o tiene 128K tokens; Claude 3.5 Sonnet 200K tokens, y Gemini 1.5 Pro 2 millones de tokens.
En los inicios de los modelos de lenguaje, estos presentaban entre 16K y 32K tokens. Esto es porque inicialmente los modelos no permitían trabajar ni con imágenes ni con documentación, si no simplemente intercambiar mensajes sencillos entre la IA y el humano. Sin embargo, en la actualidad utilizamos la IA Generativa para tareas algo más complejas como: recuperar información de un documento, responder a preguntas con un amplio contexto de un dominio específico, entre otras.
¿Qué es la ventana de contexto?
Aunque hemos dado una intuición de qué puede significar el tamaño de ventana de contexto, vamos a dar una definición algo más formal:
La ventana de contexto es la cantidad de tokens que un modelo puede considerar de una vez al generar una respuesta.
Y … ¿qué es un token?
Un token es la unidad básica de entrada y de salida de un modelo de lenguaje.
A pesar de que nosotros introduzcamos texto en lenguaje natural, el ordenador traduce estos caracteres a tokens. Aunque no es exactamente así, para que podamos entenderlo todos, un token es aproximadamente una palabra; y además, cada carácter especial (como puede ser una tilde, una coma, el símbolo «ñ», …) también supone un token. Es importante entender también que no todos los modelos de lenguaje utilizan la misma definición de token. Lo que para GPT-4o de OpenAI es un token, para Gemini de Google puede no serlo. Además, incluso dentro de un mismo proveedor como OpenAI, el concepto de token puede evolucionar a lo largo del tiempo. Si quieres hacerte una idea algo más precisa de qué es un token, te animo que entres a esta página de OpenAI.
Con cada pregunta que vamos haciendo a un modelo de lenguaje, lo que va sucediendo por debajo es que la ventana de contexto se va llenando con cada una de las interacciones que hacemos (no funciona exactamente así, somos los desarrolles quienes tenemos que encargarnos de simular esto, pero vamos a quedarnos con esta intuición).
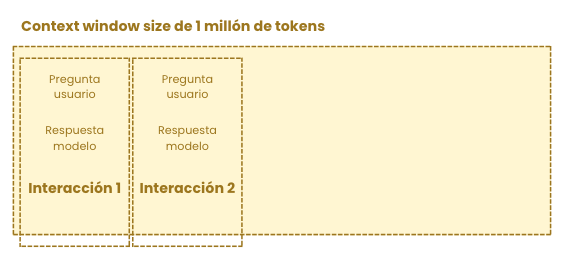
Recuerda que cada mensaje está compuesto por tokens, por lo que, cuanto más largo sea el mensaje, más tokens tendrá y más rápido llenaremos la ventana de contexto.
A lo largo de una conversación puede pasar que nos encontremos en el punto en el que hemos llenado la ventana de contexto
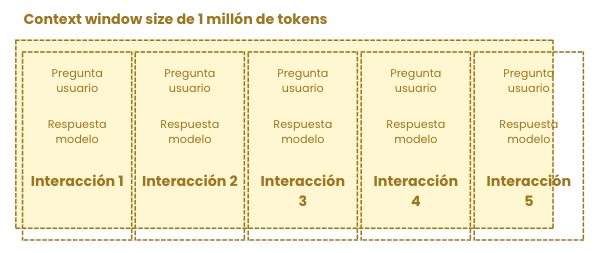
Quizás lo normal para ti (como lo era para mi) sería pensar que si la interacción 5 sucede pero no cabe en la ventana de contexto, entonces la interacción 1 desaparecería, olvidándose, para introducir la interacción 5.
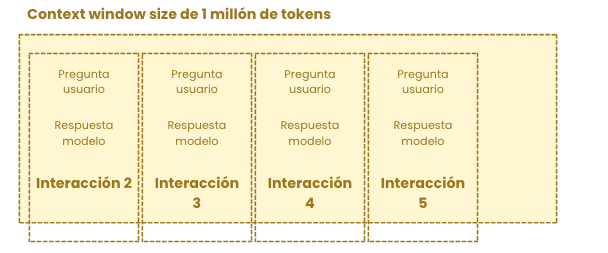
Estás 50% en lo cierto. La realidad, como comentaba antes, no es la que estoy contando al 100%. Los modelos de lenguaje solo aceptan tokens y devuelven tokens, ellos no entienden qué es el historial de la conversación, de esto nos encargamos los desarrolladores de aplicaciones de Inteligencia Artificial. Somos los desarrolladores quienes nos encargamos de recoger todos los mensajes de una conversación, quedarnos, por ejemplo, con los 20 últimos (para evitar desbordar fácilmente la ventana de contexto) y enviarlos al modelo de lenguaje.
Si a un modelo le pasamos todos los mensajes de una conversación sin aplicar ninguna técnica como la que comento, entonces obtendremos un error por haber excedido la ventana de contexto.
Conclusiones
En la actualidad lo que vamos viendo es la tendencia de los modelos de tener cada vez una mayor ventana de contexto. Esto es algo que va a continuar sucediendo. ¿Por qué?
- Una mayor ventana de contexto supone una mayor capacidad de recordar el pasado.
- Una mayor ventana de contexto supone una mayor capacidad de procesar en una sola interacción una petición más extensa (interesante cuando trabajamos con documentación)
Como sabemos las soluciones basadas en Inteligencia Artificial Generativa cada vez se integran más en el mundo empresarial debido a la reducción de costes en tiempo que supone. La mayoría de las aplicaciones empresariales implica trabajar con documentaciones extensas, por lo que, para poder dar solución a este tipo de problemáticas, es necesario una mayor ventana de contexto.
Recuerda seguirme en LinkedIn para estar al día de las últimas novedades.
Deja una respuesta